



Análisis elaborado en abril 2026
Disclaimer
La información contenida en este documento tiene únicamente fines educativos e informativos. No constituye en ningún caso una oferta, recomendación o asesoramiento financiero, de inversión, legal o fiscal. Las opiniones expresadas reflejan un análisis personal y pueden estar sujetas a cambios sin previo aviso.
Invertir en los mercados financieros conlleva riesgos, incluyendo la posible pérdida total del capital invertido. Cada lector o inversor es responsable de realizar su propia investigación y, en caso necesario, consultar con un asesor financiero registrado antes de tomar decisiones de inversión.
El autor no asume responsabilidad alguna por pérdidas o daños derivados directa o indirectamente del uso de la información aquí presentada.
Introducción
Nvidia es, hoy, la empresa de semiconductores más valiosa de la historia de la humanidad. Y posiblemente la compañía que mejor encarna la tensión fundamental del momento actual: el mercado le asigna una capitalización de $4,27 billones de dólares sobre la premisa de que la inteligencia artificial no es una moda sino una transformación estructural de la economía global, y que Nvidia estará en el centro de esa transformación por al menos la próxima década.
Esta premisa puede ser correcta. Pero también puede ser la narrativa más cara si los ASICs reemplazan a los GPUs en inferencia, si China queda bloqueada de manera permanente, o si un competidor logra romper el ecosistema CUDA.
Nvidia fue fundada en 1993 por Jensen Huang, Chris Malachowsky y Curtis Priem en Santa Clara, California, con el objetivo inicial de revolucionar los gráficos para videojuegos. Cotiza en el NASDAQ bajo el símbolo NVDA. Hoy, con más de 36.000 empleados, la compañía no vende chips: vende la infraestructura computacional sobre la que se construye la era de la IA.
La misión declarada de Nvidia: “Acelerar la computación para el beneficio de la humanidad.” Lo que empezó como un negocio de gráficas de videojuegos es hoy la columna vertebral del entrenamiento de los modelos de lenguaje más avanzados del mundo, desde GPT-4 hasta Gemini, pasando por Claude. Prácticamente toda la IA generativa que usás hoy fue entrenada en hardware de Nvidia.
Este análisis va a mostrarte por qué Nvidia construyó uno de los moats más sólidos, por qué ese moat está siendo desafiado desde adentro por sus propios clientes, y por qué la valuación actual deja poco margen de error.
Modelo de negocio
Nvidia se describe a sí misma como una empresa de “plataformas de computación acelerada”. No vende únicamente chips: vende ecosistemas completos que incluyen hardware (GPUs, NVLink, InfiniBand), software (CUDA, cuDNN, TensorRT, Triton), frameworks (NeMo, cuOpt) y servicios (DGX Cloud, NIM microservices). La integración vertical de esa stack es lo que hace al negocio extraordinariamente difícil de replicar.
¿Qué es una GPU? Una GPU (Graphics Processing Unit, o Unidad de Procesamiento Gráfico) es un chip diseñado originalmente para videojuegos. A diferencia de la CPU (el procesador principal de una computadora, que hace pocas cosas muy inteligentemente), la GPU tiene miles de núcleos pequeños que hacen millones de cálculos simples al mismo tiempo. Esa capacidad de paralelismo masivo resultó ser perfecta para entrenar inteligencia artificial: el aprendizaje de un modelo de IA es básicamente hacer el mismo cálculo matemático billones de veces. En 2012, investigadores descubrieron que las GPUs de Nvidia podían hacer ese trabajo 100 veces más rápido que cualquier alternativa. Desde ese momento, Nvidia dejó de ser una empresa de videojuegos.
Segmento 1: Data Center
El Data Center es el corazón de Nvidia. Generó $193,7B en FY2026, el 89,7% de los ingresos totales, con un crecimiento del 142% en dos años. En Q4 FY2026 solo, el segmento facturó $62,3B (+75% YoY). Las cifras son tan grandes que resultan difíciles de dimensionar: el Data Center de Nvidia por sí solo tiene ingresos anuales superiores a los de empresas como Netflix, Airbnb o Spotify.
El producto emblema de la era actual es la arquitectura Blackwell, presentada en 2024 y escalando agresivamente en 2025. El chip B200 ofrece hasta 20 petaflops de rendimiento en inferencia y 4 petabytes por segundo de ancho de banda de memoria con HBM3e. Esto lo que nos dice es qué tan rápido y bien conectado está el chip. Explico a continuación estos conceptos:
20 petaflops = puede hacer 20 millones de millones de operaciones matemáticas por segundo. Una calculadora hace una operación a la vez; este chip hace 20.000.000.000.000 simultáneamente. Toda esa potencia es lo que le permite a un modelo de IA responder preguntas complejas en segundos en lugar de horas.
4 petabytes por segundo de ancho de banda de memoria = la velocidad a la que el chip puede leer y escribir datos en su memoria. Más ancho de banda = el chip nunca espera, siempre está procesando.
HBM3e es el tipo de memoria que logra esa velocidad. HBM son las siglas de High Bandwidth Memory (memoria de alto ancho de banda), apilada en capas sobre el chip para minimizar la distancia que recorre el dato.
Los sistemas completos DGX B200, que integran 8 GPUs B200, se venden a precios que oscilan entre $300.000 y $400.000 por unidad. Los racks de datos completos (GB200 NVL72) llegan a precios de $3 millones por rack. Y la demanda supera sistemáticamente la oferta: los pedidos acumulados al cierre de Q4 FY2026 sumaban compromisos de suministro por $95,2B, más que el doble de lo registrado el trimestre anterior.

El siguiente paso es Vera Rubin, la arquitectura prevista para la segunda mitad de 2026. Jensen Huang describió en el GTC 2025 que Vera Rubin ofrecerá un salto de rendimiento de al menos 3x sobre Blackwell en ciertas cargas de inferencia, con soporte para HBM4. La cadencia de lanzamiento anual de nuevas arquitecturas es lo que Jensen llama “el ciclo de vida más rápido en la historia del chip” y es un mecanismo deliberado: cada generación vuelve obsoleta a la anterior, capturando a los clientes en un ciclo permanente de inversión. Si un cliente quiere mantenerse competitivo, practicamente cada 2 años debe reponer o actualizarse. Por ejemplo, Nvidia lanzó Hopper (H100) en 2022, Blackwell (B200) en 2024, Vera Rubin en H2 2026. Cada generación ofrece 2x-3x más rendimiento que la anterior. Para un hyperscaler como Microsoft o Google, quedarse una generación atrás significa que sus competidores pueden entrenar modelos más grandes, más rápido y más barato. El costo de no actualizarse es mayor que el costo de comprar los chips nuevos. Aunque no sea un negocio de suscripción, es uno con alta recurrencia.
Dentro del Data Center, hay una subcategoría que merece atención especial: networking. Los ingresos de networking crecieron un 263% interanual en Q4 FY2025 y siguen siendo uno de los segmentos más subestimados por los analistas. InfiniBand (tecnología adquirida con Mellanox en 2020) y NVLink son las soluciones de interconexión que permiten que miles de GPUs trabajen como una sola máquina. A medida que los clusters de entrenamiento escalan desde miles a millones de chips, la red que los conecta se convierte en tan crítica como los chips mismos. Nvidia tiene una posición dominante ahí también.
Segmento 2: Gaming
El Gaming fue el negocio que construyó a Nvidia durante 30 años, y hoy es el segmento número dos con $16B en FY2026 (+43% YoY). La línea GeForce RTX, que va desde modelos de entrada hasta la RTX 5090 lanzada en enero de 2026, domina el mercado de GPUs de consumo con una participación que históricamente supera el 80% del mercado discreto.
¿Qué es una tarjeta gráfica? Es una GPU con su propio procesador, memoria y sistema de refrigeración, diseñada para instalarse en una computadora de escritorio o laptop. Un gamer la compra porque quiere jugar videojuegos con gráficos de alta calidad a altas velocidades. Cuanto más potente la GPU, más detallados pueden ser los gráficos y más suave se ve el movimiento en pantalla.
Lo que hace interesante al Gaming hoy es la convergencia entre videojuegos e inteligencia artificial. Las tarjetas GeForce integran los mismos Tensor Cores (núcleos especializados para IA) que las GPUs de Data Center, y tecnologías como DLSS 4 (Deep Learning Super Sampling) usan IA para mejorar la calidad visual de los juegos. DLSS funciona así: en lugar de calcular cada píxel a resolución completa (lo cual es costoso), el juego renderiza a menor resolución y una red neuronal “reconstruye” la imagen a alta calidad prediciendo cómo debería verse. El resultado es calidad visual superior con menor costo computacional. AMD no puede replicar esa diferenciación sin un ecosistema de software equivalente.
Pero el Gaming importa estratégicamente por algo que va más allá de las ventas: genera desarrolladores familiarizados con CUDA. Un estudiante de ingeniería que aprende a programar para juegos usando tecnología de Nvidia eventualmente migra esas habilidades al Data Center. El Gaming es el funnel que alimenta el ecosistema, y ese ecosistema es el moat más profundo de la empresa.
Segmento 3: Professional Visualization
Professional Visualization (ProViz) incluye las GPUs de grado profesional para diseño 3D, ingeniería, simulación y efectos visuales. Generó $3,2B en FY2026 (+70% YoY), impulsado por la adopción de GPUs Blackwell en notebooks profesionales.
¿Por qué se necesita una GPU especial para trabajo profesional? Las tarjetas de gaming están diseñadas para verse bien, no para ser matemáticamente exactas. Un ingeniero de Boeing que diseña el ala de un avión necesita una GPU que certifique que los colores, geometrías y tolerancias son precisos al milímetro. Las RTX de grado profesional están certificadas para ese nivel de exactitud y son compatibles con software de ingeniería que las de gaming no soportan.
La apuesta más interesante de este segmento es Omniverse, una plataforma de software que permite crear “gemelos digitales” de objetos físicos reales. Una fábrica puede construir una réplica digital exacta de su línea de producción, simular el movimiento de robots y trabajadores, probar distintas configuraciones y optimizar la eficiencia, todo sin mover una sola máquina física. BMW, Amazon y decenas de empresas industriales ya lo usan. Es el tipo de aplicación que convierte el hardware vendido en revenue de software recurrente: una vez que tu gemelo digital corre en Omniverse, necesitás GPUs de Nvidia para siempre.
Segmento 4: Automotive
Automotive es el segmento de menor tamaño pero con mayor tasa de crecimiento. $2,3B en FY2026 (+39% YoY), impulsado por la adopción de la plataforma DRIVE Orin y DRIVE Thor en vehículos de producción. Toyota, Mercedes-Benz, Volvo, BYD y decenas de fabricantes ya integraron chips Nvidia en sus sistemas ADAS (Advanced Driver Assistance Systems). DRIVE Thor, previsto para producción en 2025-2026, ofrece hasta 2.000 TOPS de capacidad computacional para autonomía y sistemas de información y entretenimiento en el mismo chip. Si el robotaxi escala como industria en los próximos años, Nvidia tiene una posición en cada vehículo, independientemente del fabricante.
Calidad del negocio
Ventas
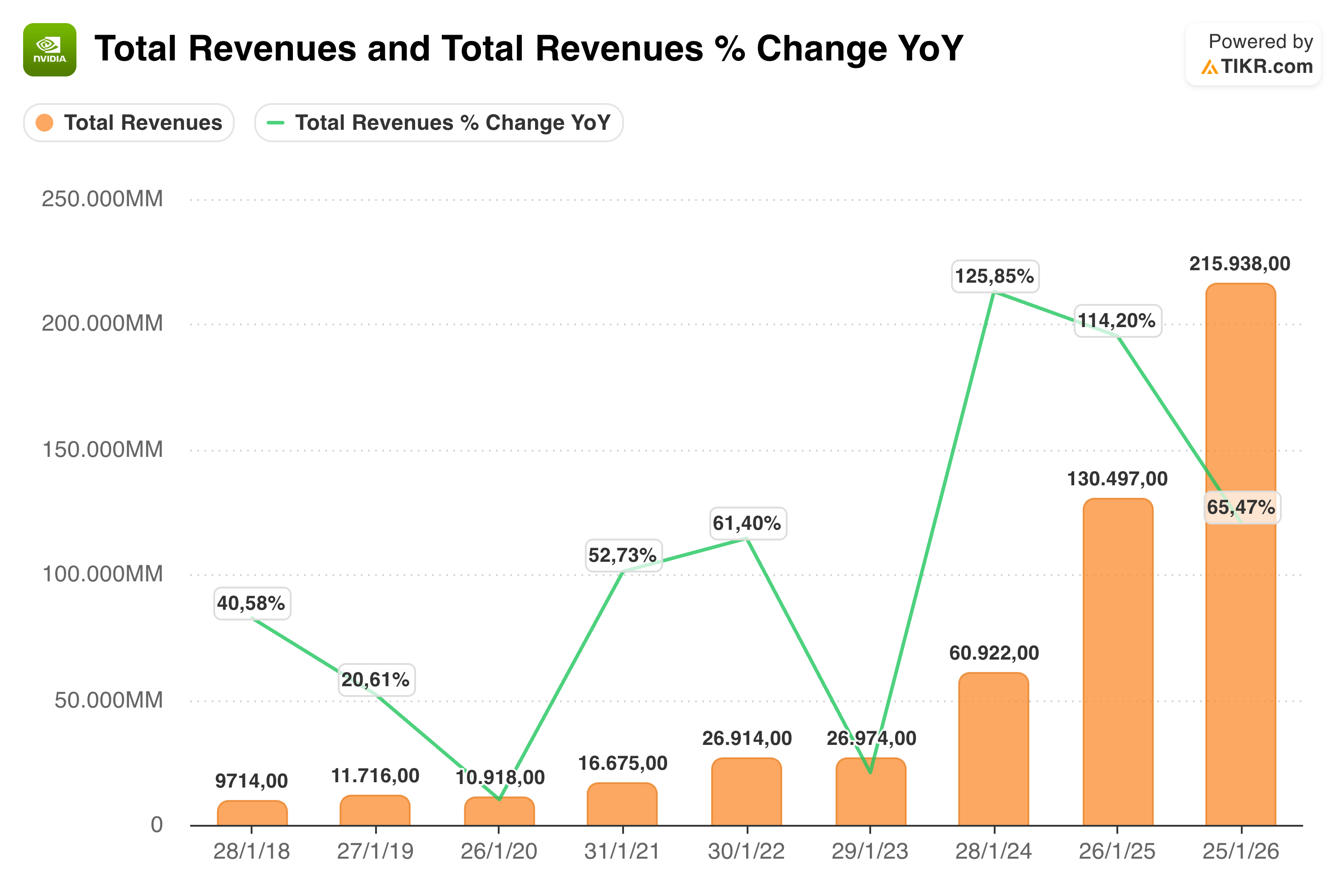
La trayectoria de ingresos de Nvidia no tiene paralelo en la historia de ninguna empresa de semiconductores. En FY2017, la compañía generaba $9,7B. En FY2023, $26,9B. El salto comenzó en FY2024 con $60,9B (+122% YoY) y se aceleró en FY2025 con $130,5B (+114% YoY). En FY2026, los ingresos alcanzaron los $215,9B, representando un crecimiento del 65% sobre una base que ya era récord, una locura. En términos absolutos, Nvidia añadió más de $85B de revenue en un solo año fiscal.
Para poner esos números en perspectiva: Intel, el semiconductor que dominó el mundo de la computación durante décadas, generó $54B en 2024. Nvidia, en el cuarto trimestre de FY2026 solo, facturó $68B. Un único trimestre de Nvidia es hoy más grande que el año entero de Intel.
La composición del crecimiento también importa. El Q4 FY2026 de $68,1B fue el resultado de un Data Center de $62,3B (+75% YoY) y de un Gaming de $6,5B (+97% YoY). Ambos segmentos batieron récords simultáneamente. El guidance para Q1 FY2027 es de $78B, lo que implicaría superar los $300B de ingresos anuales si el momentum se mantiene.
La historia de los ingresos de Nvidia entre FY2023 y FY2026 es también la historia del lanzamiento de ChatGPT: ese evento de noviembre de 2022 desbloqueó una demanda de capacidad computacional para IA que el mundo no tenía contemplada en ningún modelo de planificación de capacidad. Los hyperscalers (Microsoft, Google, Amazon, Meta) tuvieron que correr a comprar GPUs para no quedar rezagados. Nvidia era el único proveedor con el hardware y el ecosistema de software listos para escalar.
Análisis vertical
Income Statement
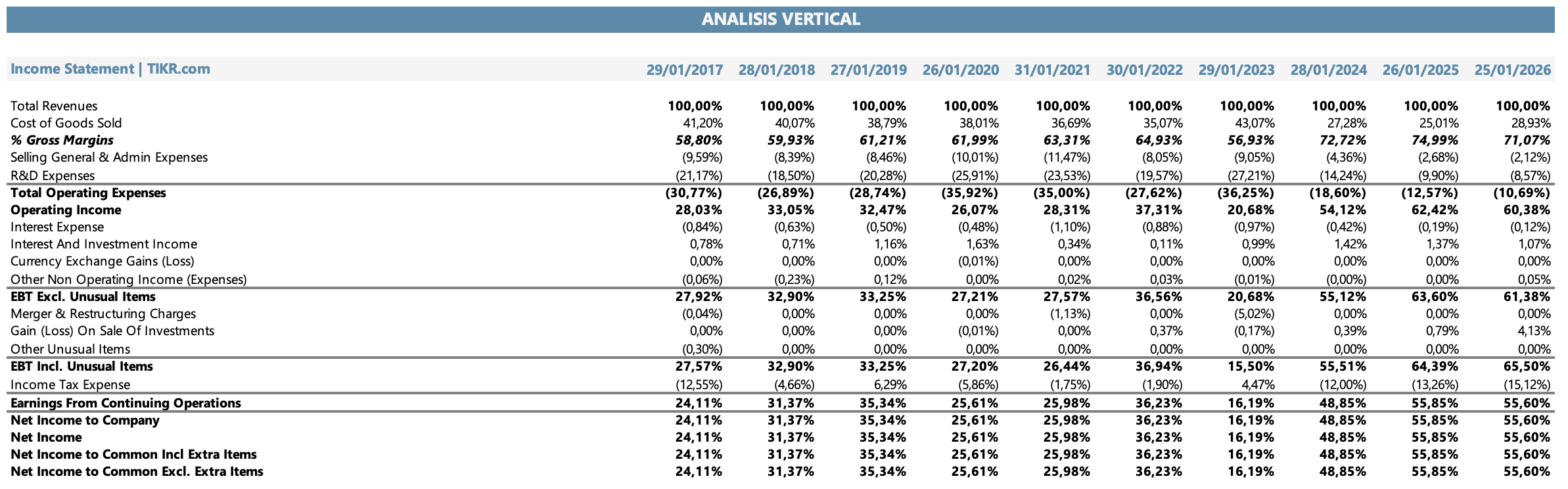
El análisis vertical del estado de resultados de Nvidia revela algo extraordinario: una empresa de hardware con márgenes de software. El margen bruto de FY2026 fue del 71%, comparable al de compañías como Microsoft o Salesforce, no al de fabricantes de chips que históricamente operan en rangos del 40-55%.
El margen bruto no siempre fue tan alto. En FY2019 y FY2020, el margen bruto de Nvidia era del 61-62%, ya sólido para la industria pero más “normal”. El salto ocurrió con el boom de IA: en FY2024, el margen saltó al 72,7%, un nivel sin precedentes para una empresa de su escala, impulsado por el pricing power extraordinario que le da ser el único proveedor con el producto y el ecosistema que el mercado necesita urgentemente.
La ligera compresión al 71,1% en FY2026 (vs. 75,5% en FY2025) responde a la transición de arquitectura: los sistemas Blackwell completos (DGX, NVL racks) tienen una estructura de costos diferente a las unidades HGX individuales de la era Hopper. Jensen lo anticipó públicamente y el mercado lo asimiló sin trauma. La pregunta es si la compresión es transitoria (asociada a la curva de ramp de Blackwell) o si señala el inicio de un ciclo más competitivo.
El margen operativo de Nvidia superó el 60% en FY2026, una cifra que convierte a la compañía en una de las más rentables en relación a sus ingresos de toda la industria tecnológica. Los gastos de administración y ventas tuvieron un peso de aproximadamente un 2% a 4% sobre las ventas en los últimos 3 años, lo que refleja que Nvidia no necesita un ejército de vendedores: los hyperscalers compiten por conseguir GPUs, no al revés.
Balance Sheet
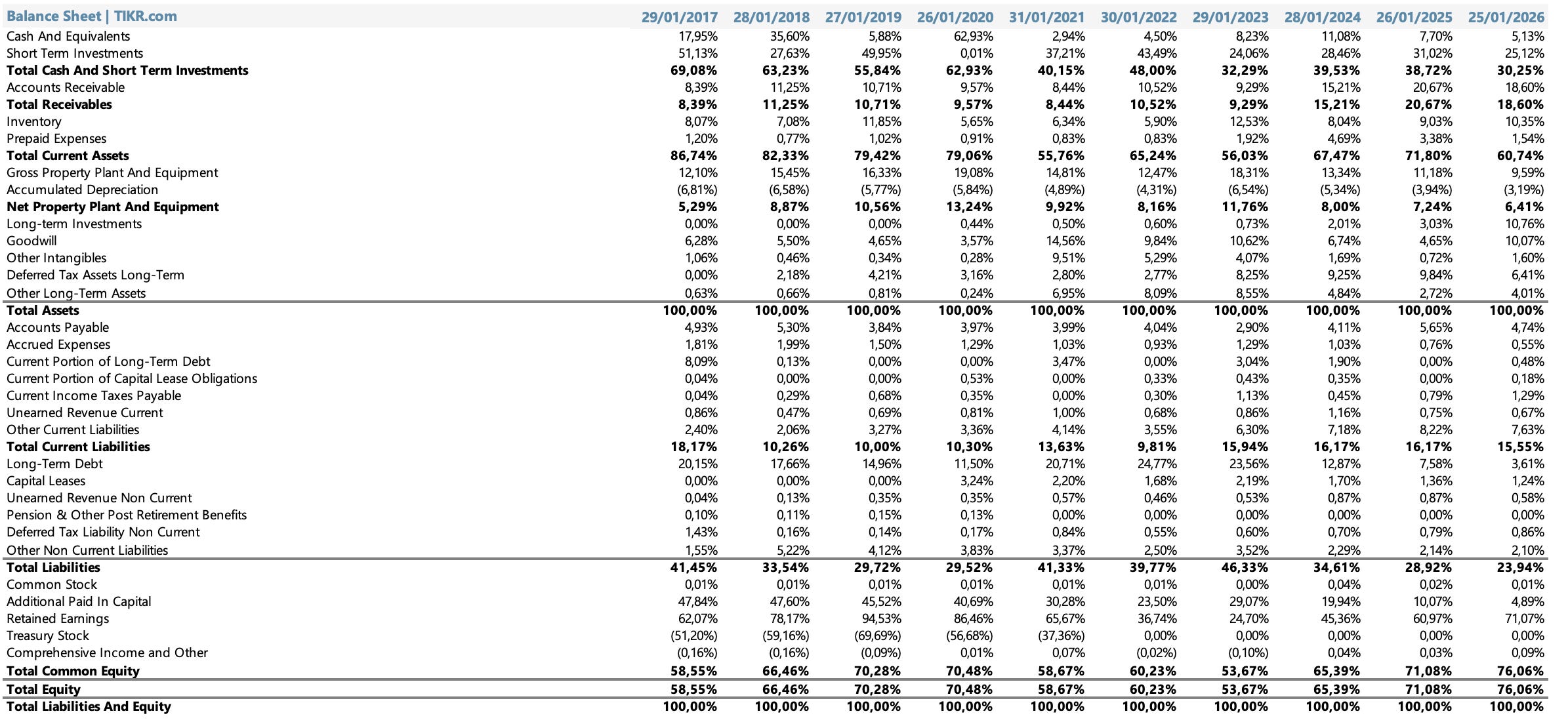
El análisis vertical del balance de Nvidia revela la transformación de una empresa que pasó de estar moderadamente endeudada y con una estructura de activos convencional, a convertirse en una máquina generadora de caja con un patrimonio neto que representa el 76% de sus activos totales.
El activo: la hegemonía de la caja
El rasgo más llamativo del activo de Nvidia a lo largo de la década es la dominancia absoluta de los activos corrientes, impulsada principalmente por la caja y las inversiones de corto plazo. En 2017, el efectivo e inversiones de corto plazo representaban el 69% del activo total, un nivel ya alto para una empresa manufacturera. Ese porcentaje fluctuó a lo largo de los años, tocando un mínimo relativo del 32% en 2023 durante el período de expansión agresiva post-pandemia, para luego recuperarse. En 2026, la caja y equivalentes más las inversiones de corto plazo representan el 30,25% del activo total, un nivel que en términos absolutos equivale a decenas de miles de millones de dólares dado el tamaño actual del balance.
Las inversiones de largo plazo merecen una mención especial: pasaron de ser prácticamente inexistentes durante toda la década a representar el 10,76% del activo total en 2026, el nivel más alto de la historia reciente. Eso refleja la decisión deliberada de Nvidia de gestionar activamente su liquidez excedente en instrumentos de mayor duración, un comportamiento típico de empresas que generan más caja de la que pueden reinvertir productivamente en el corto plazo.
La propiedad, planta y equipo neta cuenta una historia coherente con el modelo fabless: nunca superó el 13% del activo total en ningún año del período analizado, y en 2026 representa apenas el 6,41%. Esa proporción extraordinariamente baja para una empresa de su escala es la expresión numérica de una decisión estratégica tomada hace décadas: Nvidia diseña chips pero no fabrica nada, delegando toda la infraestructura industrial a TSMC y sus socios de manufactura. El resultado es un balance que no necesita anclas físicas para generar retornos extraordinarios.
El inventario escaló de manera notable en los últimos años, pasando del 5-8% histórico al 10,35% en 2026, reflejo directo de los compromisos de suministro masivos que Nvidia asumió con TSMC y los proveedores de HBM para garantizar capacidad futura. Este es el ítem del activo que más merece monitoreo: si la demanda se desacelera de manera repentina, ese inventario puede convertirse en un cargo significativo, como ya ocurrió con el episodio del H20 en China.
El pasivo: desapalancamiento estructural
El pasivo de Nvidia muestra una trayectoria de desapalancamiento. En 2017, el total de pasivos representaba el 41,45% del activo. En 2026 ese número cayó al 23,94%, prácticamente la mitad en términos relativos. La deuda de largo plazo pasó del 20,15% del activo en 2017 a apenas el 3,61% en 2026, un colapso que refleja tanto la amortización deliberada de obligaciones como la decisión de no refinanciar con nueva deuda una vez que la generación de caja propia lo hizo innecesario.
Las cuentas por pagar se mantuvieron en un rango estable del 3-6% del activo a lo largo de toda la década, sin las tensiones que suelen verse en empresas que usan los proveedores como financiamiento implícito en períodos de stress.
El patrimonio neto: la acumulación silenciosa
El equity de Nvidia es donde la historia se vuelve más elocuente. El patrimonio neto pasó de representar el 58,55% del activo en 2017 al 76,06% en 2026, impulsado fundamentalmente por la acumulación de ganancias retenidas. Las retained earnings escalaron del 62% del activo en 2017 al 71% en 2026, un indicador que en pocas palabras captura la magnitud de la creación de valor: Nvidia retiene más de lo que distribuye, y lo que retiene crece a tasas que ningún modelo de planificación hubiera proyectado hace cinco años.
En resumen…
El balance de Nvidia en 2026 es el de una empresa financieramente blindada. Poca deuda, caja abundante, patrimonio neto dominante y activos físicos mínimos en relación al tamaño del negocio. Los riesgos que persisten no son financieros sino estratégicos: la pregunta no es si Nvidia puede pagar sus obligaciones, sino si puede defender su posición en el mercado de chips de IA frente al avance de los ASICs de sus propios clientes. El balance le da toda la flexibilidad del mundo para intentarlo. Lo que no garantiza es el resultado.
Cash Flow Statement
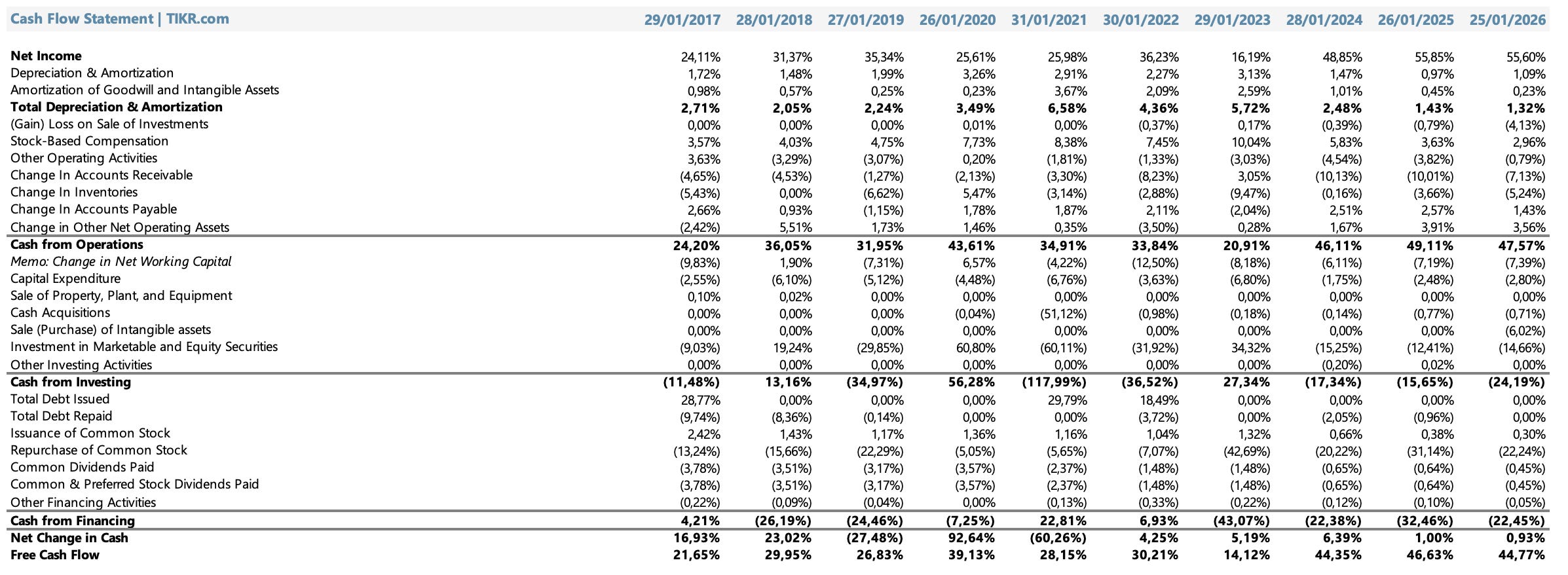
El cash flow operativo de Nvidia nunca fue negativo en ningún año del período analizado, lo cual ya es un dato notable para una empresa que atravesó ciclos de expansión agresiva, una pandemia global y restricciones de exportación. En 2017 el flujo operativo representaba el 24,20% de los ingresos. En 2026 llegó al 47,57%, casi duplicando esa proporción en una década. El pico de ese recorrido refleja exactamente el momento en que el pricing power de Nvidia se volvió casi irrestricto: cuando la demanda supera la oferta de manera estructural, cada dólar adicional de revenue se convierte en caja.
El net income como porcentaje de ingresos siguió una trayectoria similar, moviéndose del 24% en 2017 hasta el 55,60% en 2026, su nivel más alto de la historia. Lo que eso significa en términos prácticos es que Nvidia convierte más de la mitad de cada dólar que factura en ganancia neta, un ratio reservado históricamente para negocios de software puro o plataformas digitales con costos marginales cercanos a cero.
La depreciación y amortización cayó en términos relativos de manera sostenida, pasando del 2,71% de los ingresos en 2017 al 1,32% en 2026. Esa compresión no refleja menor inversión sino exactamente lo opuesto: los ingresos crecieron tan rápido que la base de activos depreciables quedó pequeña en relación al tamaño del negocio. Es la consecuencia natural del modelo fabless aplicado a escala masiva.
El stock-based compensation merece atención especial porque es un ítem que distorsiona la lectura si no se lo separa del análisis. En 2023 llegó a representar el 10% de los ingresos, el nivel más alto de la serie, antes de comprimirse al 2,96% en 2026. La reducción relativa es positiva: significa que el crecimiento del revenue superó con creces el crecimiento de la compensación en acciones, diluyendo su peso sobre el flujo de caja reportado.
El capex de 2,80% sobre ingresos en 2026 confirma lo que ya vimos en el análisis del balance: la naturaleza fabless de Nvidia hace que su necesidad de inversión en activos físicos sea estructuralmente baja. Para una empresa que generó el 47% de sus ingresos en caja operativa, destinar menos del 3% a capex es lo que produce un free cash flow del 44,77% sobre ingresos en 2026, el número más alto de toda la serie histórica y uno de los más altos que se pueden observar en cualquier empresa tecnológica de su escala.
El cash from financing cuenta la historia del ciclo completo de maduración financiera de Nvidia. En 2017 era positivo en 4,21%, todavía con emisión neta de deuda. A partir de 2019 se volvió consistentemente negativo, señal de que la empresa dejó de necesitar capital externo y empezó a devolver el excedente a los accionistas.
La recompra de acciones es la partida dominante: representó el 42,69% de los ingresos en 2023, el año en que Nvidia ejecutó el programa de recompras más agresivo de su historia, y se mantuvo en el 22,24% en 2026. Esos números son extraordinarios en términos absolutos: en un año donde Nvidia facturó $215,9B, devolvió más de $48B en recompras. Sumado a los dividendos, que se mantienen modestos en el 0,45% de los ingresos, la compañía retornó más del 43% de su free cash flow a los accionistas en FY2026.
Ratios
Liquidez

Los ratios de liquidez de Nvidia muestran una posición consistentemente sólida a lo largo de toda la década, aunque con una tendencia de moderación en los últimos años que necesita contextualizarse. El ratio corriente, que mide la capacidad de cubrir pasivos de corto plazo con activos corrientes, arrancó en 4,77x en 2017 y cerró en 3,91x en 2026. La caída desde el pico de 8,03x en 2018 no refleja deterioro financiero sino el crecimiento del pasivo corriente al ritmo de un negocio que escala agresivamente: más cuentas por pagar, más ingresos diferidos, más obligaciones operativas de corto plazo. Un ratio corriente de 3,91x sigue siendo extraordinariamente holgado para cualquier empresa manufacturera o tecnológica de su escala.
El ratio rápido, que excluye el inventario por ser el activo menos líquido, siguió una trayectoria similar: de 4,26x en 2017 a 3,14x en 2026. Y el ratio de caja, el más estricto de los tres, cerró en 1,94x, lo que significa que Nvidia podría cubrir casi el doble de sus pasivos corrientes únicamente con su efectivo e inversiones líquidas, sin necesidad de cobrar una sola factura ni vender un solo chip de inventario.
El único año que merece atención es 2023, donde los tres ratios tocaron sus mínimos de la serie (corriente 3,52x, rápido 2,61x, caja 2,03x), en un contexto de expansión acelerada del balance y acumulación de compromisos de suministro previos al boom de Blackwell. La recuperación posterior a 2023 confirma que ese mínimo fue transitorio, no estructural, y que la posición de liquidez de Nvidia se reconstruyó con la misma velocidad con que el negocio aceleró.
Solvencia

Los ratios de solvencia de Nvidia cuentan una de las historias de desapalancamiento más limpias que se pueden observar en una empresa de tecnología de su capitalización. En 2017, la deuda de largo plazo representaba el 34,42% del patrimonio neto. En 2026 ese número colapsó al 6,38%, una reducción de más de 28 puntos porcentuales en menos de una década que refleja tanto la amortización deliberada de deuda como la acumulación exponencial de equity vía ganancias retenidas.
El ratio deuda total sobre activos siguió la misma dirección: del 28,28% en 2017 al 5,52% en 2026, confirmando que el balance de Nvidia hoy está financiado de manera abrumadora con capital propio. El apalancamiento financiero (activos totales sobre equity) cayó de 1,71x a 1,31x, un nivel que prácticamente no implica riesgo de estructura de capital bajo ningún escenario macroeconómico razonable.
El ratio deuda sobre EBITDA es quizás el más elocuente de toda la sección. En 2017 era de 1,31x, un nivel ya manejable. En 2026 llegó a 0,09x, lo que en la práctica significa que Nvidia podría cancelar toda su deuda con menos de cinco semanas de EBITDA. Es un nivel de endeudamiento que hace irrelevante cualquier análisis de riesgo crediticio convencional.
La cobertura de intereses confirma ese cuadro con números que resultan casi difíciles de procesar: 503,42x en 2026, frente a los 33,40x de 2017. Por cada dólar de gasto financiero, Nvidia genera más de 500 dólares de resultado operativo. El salto desde los 21,29x de 2023 hasta los 503x de 2026 resume en un solo número la magnitud del boom de ingresos de los últimos dos años: los gastos financieros permanecieron prácticamente estables mientras el operating income se multiplicó por cinco.
Performance

Los ratios de performance miden qué tan eficientemente Nvidia convierte sus activos y su equity en caja operativa, y en este caso la serie histórica traza una curva en forma de J que captura perfectamente la narrativa del negocio. El cash flow to revenue, que relaciona el flujo operativo con los ingresos, tuvo su punto más bajo en 2023 con el 20,91% antes de dispararse al 47,57% en 2026, el nivel más alto de toda la serie. Esa recuperación no fue gradual sino exponencial, coincidiendo exactamente con el ramp de Blackwell y la consolidación del pricing power en el mercado de GPUs de IA.
El cash return on assets escaló del 13,70% en 2023 al 49,67% en 2026: por cada dólar de activo, Nvidia genera casi 50 centavos de caja operativa anual. Y el cash return on equity llegó al 65,30% en 2026, ligeramente por debajo del pico de 80,79% del año anterior, pero todavía en niveles que pocas empresas de su tamaño pueden alcanzar. La moderación respecto al pico de 2025 refleja el crecimiento del equity por retención de ganancias más que ningún deterioro operativo.
Actividad

Los ratios de actividad revelan la eficiencia operativa de Nvidia con un detalle que el análisis de márgenes no captura. Los días de inventario oscilaron entre 75 y 122 días a lo largo de la serie, cerrando en 92 días en 2026. Ese nivel, aunque superior al mínimo histórico, es coherente con los compromisos masivos de suministro que Nvidia asumió con TSMC y los proveedores de HBM: parte de ese inventario son componentes pre-comprados para garantizar capacidad futura, no stock sin salida.
Los días de cobro (DSO) se mantuvieron en el rango de 44-65 días a lo largo de toda la década, cerrando en 65 días en 2026. Es un nivel razonable para ventas corporativas de alto valor a hyperscalers y empresas tecnológicas que tienen ciclos de aprobación de pago propios. No hay señal de deterioro en la calidad de la cartera de clientes.
Los días de pago a proveedores se comprimieron de 51 días en 2018 a 40 días en 2026, reflejando que Nvidia, a medida que consolidó su posición de poder en la cadena de suministro, dejó de necesitar extender los plazos de pago como mecanismo de financiamiento implícito. Personalmente hubiese preferido que se mantengan en torno a los 50 días, aunque no es algo alarmante en una empresa de esta calidad.
El working capital creció de $6,7B en 2017 a $93,4B en 2026, el reflejo más directo del tamaño del balance. La rotación de activos totales subió de 0,70x a 1,04x, señal de que el crecimiento de los ingresos superó al crecimiento de los activos, mejorando la eficiencia general del capital desplegado.
Rentabilidad

Los ratios de rentabilidad de Nvidia trazan la curva más dramática de todo el análisis: una empresa que en 2023 tocó sus mínimos relativos de retorno antes de protagonizar una de las expansiones de rentabilidad más rápidas.
El ROA operativo pasó del 14% en 2023 al 63% en 2026, su segundo nivel más alto de la serie después del pico de 73% en 2025. Por cada dólar de activo total, Nvidia genera 63 centavos de resultado operativo anual, un número que pertenece al universo de los negocios de plataforma digital, no al de semiconductores. El ROA neto siguió la misma trayectoria, cerrando en 58% en 2026 frente al 11% de 2023, una recuperación de 47 puntos porcentuales en tres años que no tiene precedente comparable en la industria.
El ROE llegó al 76% en 2026, levemente por debajo del pico de 92% del año anterior. Esa compresión no implica deterioro: el equity creció por retención de ganancias más rápido que el net income en términos porcentuales, diluyendo el ratio desde el pico. Dicho de otra forma, Nvidia acumula tanto patrimonio que el denominador crece a una velocidad que modera el ratio aun cuando el numerador sigue siendo extraordinario.
El ROIC de 77% en 2026 es quizás el número más importante de toda la tabla. Con un costo de capital estimado en el rango del 9-10%, un ROIC de 77% implica que Nvidia destruye el spread entre retorno y costo de capital de manera tan masiva que cualquier nueva inversión que realice, siempre que mantenga la misma estructura de negocio, genera valor económico a una tasa que pocas empresas en la historia del capitalismo moderno pudieron sostener por períodos prolongados. La pregunta central es por cuántos años más puede mantenerse en ese rango antes de que la competencia de los ASICs y la maduración del mercado lo compriman hacia niveles más convencionales.
Equipo directivo
Jensen Huang, CEO y cofundador

Jensen no es simplemente el CEO de una empresa exitosa: es el arquitecto de uno de los pivotes estratégicos más extraordinarios de la historia corporativa moderna, el hombre que tomó una empresa de videojuegos y la convirtió en la infraestructura sobre la que se construye la inteligencia artificial global.
Nació el 17 de febrero de 1963 en Tainan, Taiwan. Su infancia estuvo marcada por las dificultades: cuando tenía 9 años, sus padres lo enviaron con su hermano a vivir con un tío en Tacoma, Washington. Una confusión llevó a que terminara en el Oneida Baptist Institute de Kentucky, un reformatorio religioso para jóvenes problemáticos. Jensen, sin haber cometido ninguna falta, limpió baños todos los días y fue víctima de bullying sistemático. Ese período forjó en él un carácter que los que lo conocen describen como resiliente hasta la testarudez.
Se graduó en ingeniería eléctrica de Oregon State University en 1984 y completó su maestría en Stanford. Trabajó en Advanced Micro Devices (AMD) y LSI Logic antes de fundar Nvidia en abril de 1993 junto a Chris Malachowsky y Curtis Priem. Empezaron en un Denny’s, con una servilleta donde dibujaron los primeros esbozos de la arquitectura de lo que sería Nvidia.
El primer gran producto fue el RIVA 128 en 1997, y casi no llegaron a lanzarlo. El chip anterior había apostado a procesar triángulos con un método alternativo al estándar de la industria, y Microsoft estableció que DirectX solo soportaría triángulos convencionales. Nvidia estuvo a semanas de la quiebra. Jensen tomó la decisión de redirigir todos los recursos al RIVA 128 con un método nuevo y lo lanzó en tiempo récord. Fue la primera de muchas apuestas existenciales que ganó.
En 2006 lanzó CUDA (Compute Unified Device Architecture), una plataforma de software que permitía usar GPUs para cómputo de propósito general, más allá de los gráficos. En ese momento casi nadie entendió para qué servía. Las descargas de CUDA cayeron. Los inversores preguntaban por qué gastaban en algo sin mercado aparente. Jensen usaba el término “mercado de cero billones de dólares” para describir las apuestas que valía la pena hacer: tan grandes que los competidores no se molestaban en entrar.
El punto de inflexión llegó en 2012 cuando AlexNet, el primer modelo de deep learning moderno desarrollado por Geoffrey Hinton y sus estudiantes en Toronto, ganó el concurso ImageNet con una ventaja arrolladora. El modelo fue entrenado en GPUs de Nvidia. Jensen entendió de inmediato las implicaciones: “Si puede aprender a reconocer imágenes, puede aprender cualquier función compleja.” Desde ese momento, Nvidia redirigió toda la empresa hacia la IA.
En 2016 fue en persona al GTC (GPU Technology Conference) a entregar el primer DGX-1, el primer supercomputador diseñado específicamente para IA, a un destinatario especial: OpenAI, que era entonces una organización sin fines de lucro con una sede pequeña en San Francisco. Alguien en la audiencia se acercó después de la presentación y le dijo que le gustaría uno. Era Elon Musk.
Lo que Jensen construyó a lo largo de 30 años es una de las plataformas tecnológicas más profundas de la historia. No solo chips: CUDA, cuDNN, TensorRT, NeMo, Omniverse, DRIVE, la red de investigadores universitarios, los cursos de DLI (Deep Learning Institute), los partnerships con los hyperscalers. Cuando el mundo necesitó infraestructura para la IA, Jensen ya la había construido durante 15 años antes de que nadie más la pidiera. Eso es la esencia de lo que hace un fundador-CEO con visión de largo plazo.
Jensen tiene hoy 62 años y sigue siendo tan intenso como siempre. Su estilo de management es conocido por ser exigente en extremo (”the Wrath of Jensen” es un término que existe en la cultura interna de Nvidia). No le gustan las jerarquías: prefiere que sus empleados le manden emails cortos con lo que están haciendo esa semana antes que tener sistemas de reporte formales. Su máxima de management es operar siempre al “speed of light”: calcular el tiempo mínimo posible para hacer algo sin restricciones, y luego trabajar para acercarse a ese ideal.
La pregunta que todo inversor debe hacerse es: ¿qué le pasa a Nvidia sin Jensen Huang? La respuesta honesta es que nadie lo sabe, porque Jensen no tiene sucesor identificado públicamente y la empresa no ha necesitado pensar en ese escenario. Es el mayor riesgo de concentración de personas que existe en cualquier empresa de su capitalización.
Colette Kress, CFO
Colette Kress es la CFO de Nvidia desde 2013, con una trayectoria previa como CFO en Cisco y antes en Texas Instruments. Es reconocida como una de las ejecutivas financieras más sólidas del sector tecnológico: sus comunicaciones con inversores son extraordinariamente claras y precisas, y maneja la volatilidad de la compañía con consistencia notable. La calidad del CFO Commentary trimestral de Nvidia, donde se desglosan los ingresos por segmento y geografía con un nivel de detalle superior al de sus pares, es en gran medida su obra.
Competitividad
Análisis de la industria
El mercado de chips de IA es uno de los de mayor momentum de crecimiento que existe hoy. El total de inversión en capex de IA de los cuatro grandes hyperscalers (Microsoft, Google, Amazon y Meta) en 2025 superó los $250B, y los compromisos para 2026 y 2027 son aún mayores. Una fracción significativa de ese gasto va directamente a GPUs de Nvidia.
El mercado global de semiconductores para IA era de aproximadamente $100B en 2024 y se proyecta que supere los $300B hacia 2028, con tasas de crecimiento anuales del 30-40% dependiendo de la fuente y el escenario. El factor más incierto en esas proyecciones es la proporción que corresponde a GPUs versus ASICs personalizados.
La variable más importante para entender este mercado es la diferencia entre entrenamiento e inferencia. El entrenamiento de un modelo de IA requiere procesar cantidades masivas de datos para ajustar miles de millones de parámetros: es una carga que necesita máxima flexibilidad y potencia computacional, y los GPUs de Nvidia son, por consenso, la mejor herramienta disponible. La inferencia, en cambio, consiste en correr el modelo ya entrenado para responder preguntas: es una carga más predecible, repetitiva y sensible al costo por token. Y ahí es donde los ASICs (chips de propósito específico) tienen una ventaja natural.
Esta distinción es crucial para el futuro de Nvidia: si el mercado de IA madura hacia la inferencia masiva (como es inevitable), y los ASICs capturan ese mercado, Nvidia puede retener el dominio en entrenamiento (quizás el 20-25% del compute total) pero perder el mercado de inferencia (el otro 75-80%). Ese es el escenario de riesgo más concreto que el inversor debe incorporar.
El moat de CUDA: la fortaleza más difícil de asediar
En 2006, Nvidia lanzó CUDA (Compute Unified Device Architecture). Para entender por qué eso cambió todo, hay que recordar el problema que existía antes: las GPUs tenían miles de núcleos capaces de hacer cálculos en paralelo, pero programarlos era extremadamente difícil. Requería conocimientos muy específicos de gráficos que la mayoría de los científicos e ingenieros no tenían.
CUDA fue el traductor universal. Creó una interfaz de programación similar a C, el lenguaje más común en el mundo, que permitió a cualquier programador aprovechar esos miles de núcleos sin saber nada de gráficos. De repente, físicos, biólogos, economistas e ingenieros podían usar las GPUs de Nvidia para sus propios cálculos. Y los investigadores de inteligencia artificial, que necesitaban exactamente ese tipo de paralelismo masivo, empezaron a construir sobre esa base.
El resultado fue un ecosistema que hoy tiene más de 4 millones de desarrolladores escribiendo código en CUDA. Cada universidad que enseña machine learning enseña CUDA. Cada paper académico sobre IA tiene código en CUDA. Los dos frameworks de IA más usados en el mundo, PyTorch (de Meta) y TensorFlow (de Google), usan CUDA internamente.
Sobre CUDA, Nvidia construyó además un ecosistema de librerías especializadas que acelera cada aspecto del trabajo de IA: cuDNN optimiza las operaciones matemáticas de las redes neuronales hasta 10 veces más que si las programaras desde cero, TensorRT optimiza los modelos ya entrenados para que respondan más rápido en producción, y NCCL coordina la comunicación entre miles de GPUs trabajando en paralelo. Todas son gratuitas, lo que no es generosidad sino estrategia: cada desarrollador que las usa se vuelve más dependiente del hardware de Nvidia.
Lo que hace al moat de CUDA casi invulnerable no es el código en sí. Lo que lo hace difícil de replicar es la inercia del ecosistema acumulada durante 20 años. Migrar todo ese código de producción a una alternativa como ROCm (el equivalente de AMD) no es una decisión técnica: es un proyecto de años con riesgo de regresión de rendimiento en cada paso, y los clientes que gastan billones de dólares en capex no se dan ese lujo. Jensen Huang lo resume mejor que nadie: “Lo que construimos no es un castillo con fosos. Es una red. Y cuantos más nodos tiene la red, más difícil es desconectarte de ella.”
Principales competidores
AMD (Advanced Micro Devices)
AMD es el rival más directo de Nvidia en el mercado de GPUs para IA y el único fabricante de chips que ofrece una alternativa de propósito general a escala. Su línea Instinct MI300X (lanzada en 2024) y el MI350 (escalando en 2025) son los primeros chips de AMD que algunos hyperscalers están desplegando como alternativa parcial a los H100/H200 de Nvidia. Microsoft y Meta han reportado despliegues de MI300X para ciertas cargas de trabajo.
La limitación de AMD no es el hardware, que en ciertos benchmarks de memoria y ancho de banda es competitivo con Nvidia. La limitación es ROCm, el equivalente de CUDA de AMD. ROCm tiene menos del 15% del soporte de librerías y frameworks que CUDA, y migrar un modelo entrenado en PyTorch+CUDA a ROCm requiere trabajo de ingeniería significativo con rendimiento incierto. Los clientes que necesitan certeza de resultado por los que pagan billones de dólares en capex no pueden darse el lujo de experimentar con alternativas no probadas. Eso le da a Nvidia tiempo para consolidar ventaja mientras AMD construye su ecosistema.
El MI450 (”Helios”) previsto para Q3 2026 y el MI500 para 2027 son la apuesta de AMD por cerrar la brecha. Lisa Su, la CEO de AMD, es una ejecutiva extraordinaria que demostró con x86 que puede recuperar mercado perdido si le da el tiempo suficiente. La pregunta es si el tiempo es el aliado de AMD o de Nvidia en un mercado donde cada año de ventaja vale miles de millones en revenue.
AMD opera en tres segmentos principales: Data Center ($16,6B en 2025, 48% de ingresos, +32% YoY), Client & Gaming ($14,6B, 42%, +51% YoY) y Embedded ($3,5B, 10%, -3% YoY). El total de ingresos en 2025 fue de $34,6B (+34% YoY), con récords en Data Center (EPYC CPUs e Instinct GPUs) y en Client (Ryzen). La historia de AMD en 2025 es la de una empresa que finalmente convenció al mercado de que puede escalar su negocio de IA de manera sostenida, con OpenAI como el hito más significativo: la startup de IA anunció a AMD como socio preferido para desplegar 6 GW de GPUs.
NVIDIA vs AMD:
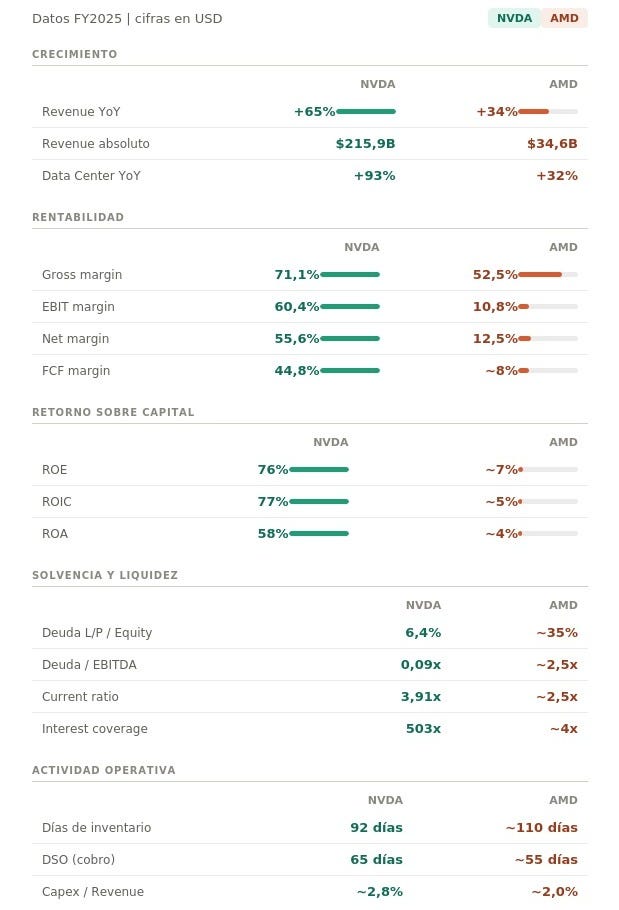
El cuadro de arriba habla por sí solo, pero hay un detalle que los porcentajes solos no capturan y que vale la pena remarcar. Nvidia creció un +65% sobre una base de $130B de ingresos, lo que implica que añadió más de $85B de revenue en un solo año fiscal. AMD creció un +34% sobre una base de $25B. Ambos números son impresionantes en términos relativos, pero la escala del crecimiento absoluto de Nvidia no tiene precedente en la historia de los semiconductores: un año de crecimiento incremental de Nvidia equivale a dos veces y media el negocio entero de AMD.
En cuanto a rentabilidad, la distancia entre ambas empresas es abismal. Nvidia convierte el 71% de cada dólar que factura en ganancia bruta, el 60% en resultado operativo y el 45% en caja libre. AMD opera con un gross margin del 52%, un EBIT del 11% y un FCF margin cercano al 8%. No son dos empresas en la misma liga: son dos modelos de negocio con estructuras de rentabilidad radicalmente distintas. Esa diferencia no es solo de escala sino de pricing power: Nvidia puede cobrar lo que quiere porque no tiene sustituto real. AMD todavía compite parcialmente por precio.
El cuadro de retorno sobre capital es el que mejor resume todo. Nvidia tiene un ROIC del 77%, AMD del ~5%. Eso no significa que AMD sea un mal negocio. Significa que Nvidia está en un momento de rentabilidad extraordinaria que difícilmente se sostiene indefinidamente, y que AMD todavía está absorbiendo el costo de capital de la adquisición de Xilinx. En 2-3 años, si el deal con OpenAI escala como está proyectado, esa brecha debería comprimirse. Pero por ahora los números cuentan una historia muy clara: Nvidia genera valor económico a una velocidad sin comparación en la industria, mientras AMD construye las bases para competir en la próxima fase del ciclo de IA.
Google (TPU Ironwood)
Google tiene la ventaja de haber sido el pionero en ASICs para IA. Su TPU (Tensor Processing Unit) lleva 10 generaciones y la versión más reciente, TPU Ironwood (v7), lanzada en noviembre de 2025, ofrece 4.614 teraflops por chip, comparable al rendimiento de los Blackwell en ciertas cargas. La ventaja principal del TPU sobre el GPU no es el rendimiento pico sino la eficiencia energética: Google estima una mejora del 2x en rendimiento por watt respecto a la generación anterior.
El TPU tiene una limitación fundamental: solo está disponible en Google Cloud. Las empresas que quieren usar TPUs deben correr sus cargas de trabajo en GCP, lo que los excluye de despliegues on-premise y multi-cloud. Esa restricción limita el mercado addressable de los TPUs a los clientes que ya están o están dispuestos a estar en Google Cloud.
El dato más relevante del ecosistema de TPUs es que Anthropic cerró el mayor deal de TPUs en la historia de Google en noviembre de 2025: comprometió cientos de miles de TPUs Trillium para 2026, escalando hacia un millón para 2027. Eso implica que la inferencia de Claude corre mayoritariamente en TPUs, no en GPUs de Nvidia. Es la primera señal concreta, a escala real, de que los ASICs pueden reemplazar a los GPUs en producción.
Amazon Web Services (Trainium)
AWS tiene dos familias de chips personalizados para IA: Trainium para entrenamiento e Inferentia para inferencia. Trainium3, lanzado en diciembre de 2025 en 3nm, ofrece 2,52 petaflops de compute FP8 con 144GB de HBM3e. En octubre de 2025, CNBC documentó el primer datacenter de AWS donde Anthropic entrena modelos en medio millón de chips Trainium2, el de New Carlisle, Indiana.
La adopción interna de Trainium en AWS todavía es limitada como proporción del total: datos internos de AWS de 2024 mostraban que Trainium representaba apenas el 0,5% del uso de GPUs de Nvidia en su plataforma. Pero la tendencia es clara: AWS no construye esa infraestructura para no usarla, y el deal para integrar Trainium4 con NVLink de Nvidia (anunciado en re:Invent 2025) sugiere que el futuro puede ser una coexistencia más que una sustitución.
Meta, Microsoft, OpenAI y los ASICs del futuro
Meta está desarrollando el MTIA (Meta Training and Inference Accelerator) para acelerar sus cargas de recomendación y generativa. Microsoft tiene el Maia 100 para Azure y Copilot. OpenAI, con Broadcom como socio de diseño, planea lanzar su propio chip en 2026. El patrón es universal: cada hyperscaler que puede costear el R&D (el diseño de un ASIC parte de decenas de millones de dólares) está intentando reducir su dependencia de Nvidia.
El argumento de los bulls de Nvidia contra esta amenaza es sólido: los ASICs son óptimos para cargas de trabajo estables y predecibles (inferencia de un modelo fijo), pero los GPU son insustituibles para investigación, prototipado y entrenamiento de nuevas arquitecturas (donde la flexibilidad es crítica). Los hyperscalers van a seguir necesitando GPUs de Nvidia para sus labs de investigación independientemente de lo que hagan con inferencia de producción.
El argumento de los bears también es sólido: si el 75-80% del compute de IA eventualmente es inferencia, y los ASICs capturan el 50-60% de ese mercado, el TAM real de Nvidia es una fracción del que descuenta la valuación actual.
El factor DeepSeek
El 27 de enero de 2025 fue uno de los días más dramáticos en la historia bursátil de Nvidia: el anuncio del modelo DeepSeek-R1, una startup china que desarrolló un modelo de lenguaje de capacidad similar a GPT-4 con un presupuesto declarado de $6M en compute, borró $589B de capitalización de mercado de Nvidia en un solo día. Fue la mayor destrucción de valor en un día en la historia del mercado bursátil.
La narrativa detrás del pánico: si los modelos de IA pueden ser entrenados con muchos menos chips, la demanda futura de GPUs de Nvidia puede ser mucho menor de lo proyectado.
La realidad es más matizada. DeepSeek usó técnicas de eficiencia (distilación de modelos, Mixture of Experts optimizado) que son legítimas y relevantes. Pero el costo de $6M no incluye el costo de hardware ni el preentrenamiento. El modelo fue desarrollado con GPUs de Nvidia (H800, la versión restringida para China). Y más importante: la demanda de compute en IA se comporta como la Paradoja de Jevons: cuando la eficiencia mejora y los modelos son más baratos de entrenar, el número de modelos que se entrenan y las aplicaciones que se construyen sobre ellos crece más que proporcionalmente. DeepSeek demostró que la IA puede ser más eficiente; eso no implica que la demanda de compute vaya a caer.
Jensen Huang lo describió en la conference call de Q4 FY2025: “El razonamiento del modelo amplifica la demanda de compute porque requiere más inferencia por pregunta. Los modelos más eficientes hacen posibles aplicaciones que antes eran imposibles por costo. El resultado es más demanda, no menos.” La acción se recuperó completamente del flash-crash de DeepSeek en los meses siguientes.
La restricción de exportación a China
El riesgo geopolítico más concreto para Nvidia es la política de restricciones de exportación del gobierno americano hacia China. En FY2022, China representaba el 26% de los ingresos de Nvidia ($7,1B de $26,9B). En FY2025, ese número cayó al 13% ($17,1B de $130,5B), y parte de esa caída se explica por los controles que bloquearon la venta de los chips más avanzados.
En abril de 2025, el gobierno americano restringió las exportaciones del H20, el chip diseñado específicamente para el mercado chino dentro de los límites regulatorios anteriores. El resultado fue el cargo de $4,5B que Nvidia registró por inventario y compromisos de compra inmovilizados. China ya no puede comprar los productos de Nvidia que necesita para competir en IA de frontera.
Este riesgo tiene dos lecturas. La pesimista: cualquier escalada adicional en las restricciones puede eliminar permanentemente el 13% del revenue y cerrar un mercado de $1,4B de personas que eventualmente demandará infraestructura de IA. La optimista: la demanda que China no puede satisfacer con Nvidia la satisface con alternativas domésticas (Huawei Ascend, Cambricon), que son inferiores, lo que ralentiza el desarrollo de IA en China y preserva la ventaja americana. Nvidia pierde ingresos en el corto plazo pero el ecosistema occidental fortalece su moat.
Análisis FODA
Fortalezas
• Moat de ecosistema insuperable: CUDA, cuDNN, TensorRT, NeMo y el ecosistema de millones de desarrolladores son barreras de switching que toman años en construir y potencialmente décadas en desmontar.
• Márgenes extraordinarios: 71% de margen bruto y 50%+ de margen operativo son niveles de software. Reflejan pricing power genuino de un proveedor con demanda mayor que oferta.
• Liderazgo en el ciclo de innovación: Roadmap Blackwell → Vera Rubin → Rubin Ultra establece un ritmo anual que mantiene perpetuamente obsoleto al competidor que tarda 18-24 meses en lanzar una alternativa.
• Integración vertical creciente: Networking (InfiniBand, NVLink), software (CUDA stack, NIM), sistemas (DGX, HGX), servicios (DGX Cloud). Cada capa adicional dificulta la sustitución.
• FCF extraordinario: $97B en un año fiscal son el resultado de un negocio que genera caja más rápido de lo que puede reinvertirla productivamente.
Debilidades
• Concentración en un solo segmento: El 90% de los ingresos vienen del Data Center y de un puñado de clientes (Microsoft, Google, Amazon, Meta). Una desaceleración en el capex de AI de los hyperscalers impacta directamente en los resultados.
• Dependencia total de TSMC: Nvidia es fabless y todo su proceso de fabricación avanzado pasa por TSMC en Taiwan. Un conflicto geopolítico o un accidente en las plantas puede interrumpir la cadena de suministro sin alternativa inmediata.
• Key-man: Jensen Huang es irreemplazable en el corto plazo y no tiene sucesor identificado. Es el mayor riesgo de concentración de personas de cualquier empresa de $4T en el mundo.
• Exposición a ciclos de capex: Los hyperscalers pueden moderar el gasto si sus propios negocios de IA no generan el retorno esperado. Un “AI winter” afectaría dramáticamente a Nvidia.
Oportunidades
• Agentic AI: La transición de modelos que responden preguntas a agentes que ejecutan tareas autónomas multiplica la demanda de inferencia por factor de 10x-100x según algunas estimaciones. Jensen llama a esto la “tercera transición” de la industria.
• IA física (robots, autos autónomos): DRIVE Thor para automotriz y Jetson para robótica son las apuestas de Nvidia en el mundo físico. Si el robotaxi y los robots industriales escalan, Nvidia tiene posición en cada vehículo y cada robot.
• Soberanía de IA: Cada gobierno del mundo quiere su propio “AI factory”. Francia, Japón, Arabia Saudita, India, y decenas más están invirtiendo en infraestructura nacional de IA. Esos proyectos usan hardware de Nvidia.
• Omniverse y gemelos digitales: La simulación industrial en tiempo real es un mercado emergente donde Nvidia tiene ventaja tecnológica. Cada fábrica que construye su gemelo digital en Omniverse es un cliente perpetuo de GPUs y software.
Amenazas
• Migración a ASICs en inferencia: Si Google, Amazon, Meta y OpenAI migran el 50-60% de su inferencia a ASICs propios, el TAM de Nvidia puede ser materialmente menor de lo que el mercado descuenta.
• Restricciones de exportación escalonadas: Cada ronda adicional de controles puede cortar un segmento más de mercado chino o incluso afectar a países que compran hardware chino.
• AMD con ecosistema maduro: Si ROCm logra paridad de soporte de librerías con CUDA en 2027-2028, el precio diferencial entre GPUs de AMD y Nvidia se convierte en el criterio de decisión. Los hyperscalers no tienen lealtad de marca si el producto funciona igual.
• “AI bubble”: Si la monetización de la IA decepciona y los hyperscalers recortan capex, el ajuste en los ingresos de Nvidia puede ser violento dado el nivel de expectativas incorporadas en la valuación.
Las cinco fuerzas de Porter
1. Rivalidad entre competidores existentes: BAJA-MEDIA
En el corto plazo, la rivalidad efectiva en GPUs de IA de frontera es baja: AMD es el único competidor con un producto de propósito general, y su cuota de mercado en Data Center de IA es estimada en 5-8%. Sin embargo, la dinámica está cambiando: AMD está acelerando su roadmap, los ASICs de los hyperscalers son competencia real en inferencia, y startups como Cerebras y Groq compiten en nichos específicos. La rivalidad es baja hoy, pero puede ser media en 2027-2028 si AMD y los ASICs ganan tracción.
2. Amenaza de nuevos entrantes: BAJA
Las barreras de entrada al mercado de GPUs de IA son extraordinariamente altas. Diseñar un chip competitivo requiere equipos de ingeniería de cientos de personas con experiencia en arquitecturas GPU (que CUDA lleva 20 años acumulando). Luego hay que fabricarlo en TSMC o Samsung, lo que requiere relaciones y compromisos de capacidad que toman años en construir. Y después viene el ecosistema de software: sin miles de librerías optimizadas, ningún chip atrae a los clientes que tienen código existente en CUDA. El único vector de entrada viable es el ASIC específico de un hyperscaler, que ya no es un “nuevo entrante” sino un cliente que se convierte en competidor parcial.
3. Poder de negociación de los proveedores: MEDIA
El proveedor más crítico de Nvidia es TSMC, que fabrica prácticamente todos sus chips avanzados. TSMC tiene pricing power porque es el único fabricante capaz de producir chips en proceso avanzado (3nm, 2nm) a escala. Sin embargo, la relación es mutuamente dependiente: Nvidia es uno de los mayores clientes de TSMC, y perderlo sería un shock para la taiwanesa. SK Hynix y Samsung, como proveedores de HBM (memoria de alta velocidad), tienen también poder de negociación significativo: la escasez de HBM es uno de los cuellos de botella en la producción de GPUs de Nvidia.
4. Poder de negociación de los clientes: BAJA-MEDIA (por ahora)
En el mercado actual, los clientes tienen poco poder de negociación porque la demanda supera la oferta: hay cola de espera para GPUs Blackwell y los precios los fija Nvidia. Sin embargo, eso puede cambiar. Los hyperscalers tienen escala suficiente para costear el desarrollo de ASICs propios (Google ya lo hizo, Amazon también, Meta y OpenAI van por ese camino). A medida que las alternativas maduren, el poder de negociación de los clientes va a crecer. El indicador a seguir es el margen bruto de Nvidia: si cae de manera sostenida, es la primera señal de que el pricing power se está erosionando.
5. Amenaza de productos sustitutos: MEDIA-ALTA
Este es el factor más relevante para el análisis de largo plazo de Nvidia. Los ASICs son sustitutos funcionales de los GPUs en cargas de trabajo de inferencia, con mejor eficiencia energética y menor costo por inferencia. Si bien no reemplazan al GPU en entrenamiento y prototipado, el grueso del compute de IA en producción es inferencia. La pregunta no es si los ASICs van a sustituir a los GPUs en algo, sino en cuánto del mercado total lo van a hacer y en qué horizonte temporal.
Valoración
Como siempre, elaboré un modelo de descuento de flujo de efectivo (DCF) con dos métodos:
Perpetuity Method
Terminal EBITDA Multiple
El modelo está proyectado a 10 años, que es el plazo en el que considero que el crecimiento se normalizará para llegar a un estado estable. En el primer método, luego de los años proyectados, asumo un crecimiento perpetuo del 2,5%, aproximadamente en línea con el crecimiento de largo plazo de la economía global. Para el segundo método, seleccioné un múltiplo EBITDA de salida de 14x para el Base Case, levemente por debajo del múltiplo actual de 16x. Un comentario sobre esto: el múltiplo actual de 16x refleja un mercado golpeado por la incertidumbre macro. La selección de 14x está basada en que lo considero un múltiplo apropiado para una empresa con las características de Nvidia una vez que alcance un estado de madurez, acorde a la dinámica de largo plazo del sector.
Entre los drivers principales del modelo:
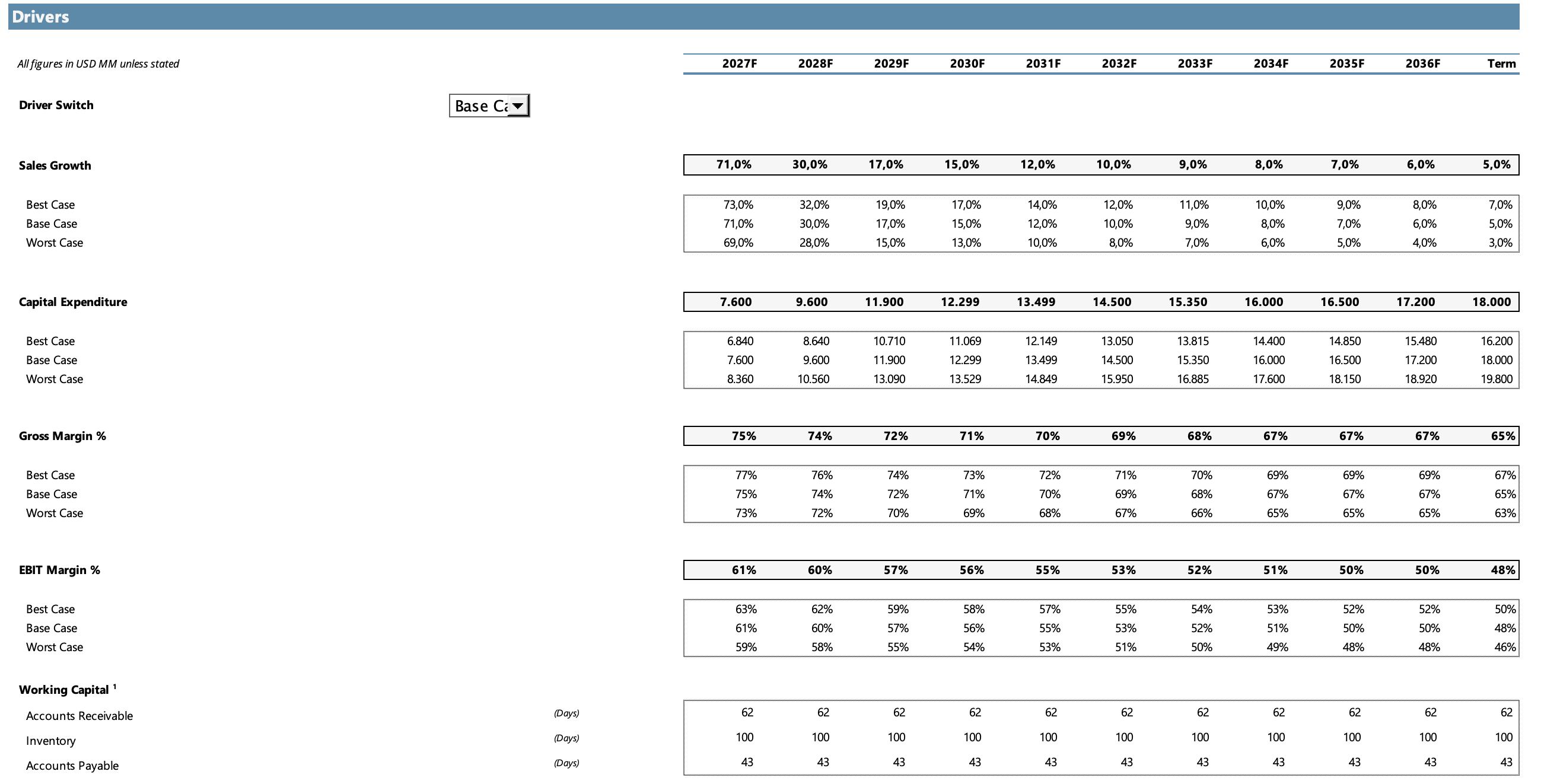
Crecimiento de ventas: las proyecciones de los primeros tres años están basadas principalmente en el consenso de analistas. Para el resto del período proyecté un descenso gradual hasta llegar a un crecimiento del 5% en el escenario base, reflejando la inevitable desaceleración de un negocio que madura.
Capex: se mantiene en línea con los niveles actuales como porcentaje de ventas, coherente con el modelo fabless de Nvidia, que diseña sus chips pero delega toda la manufactura a TSMC y sus socios de producción.
Márgenes bruto y EBIT: la lógica es consistente con la de las ventas. Los márgenes actuales se irán comprimiendo gradualmente hasta llegar a niveles más acordes a un sector maduro con menor pricing power, reflejando la presión competitiva creciente de los ASICs personalizados de los hyperscalers.
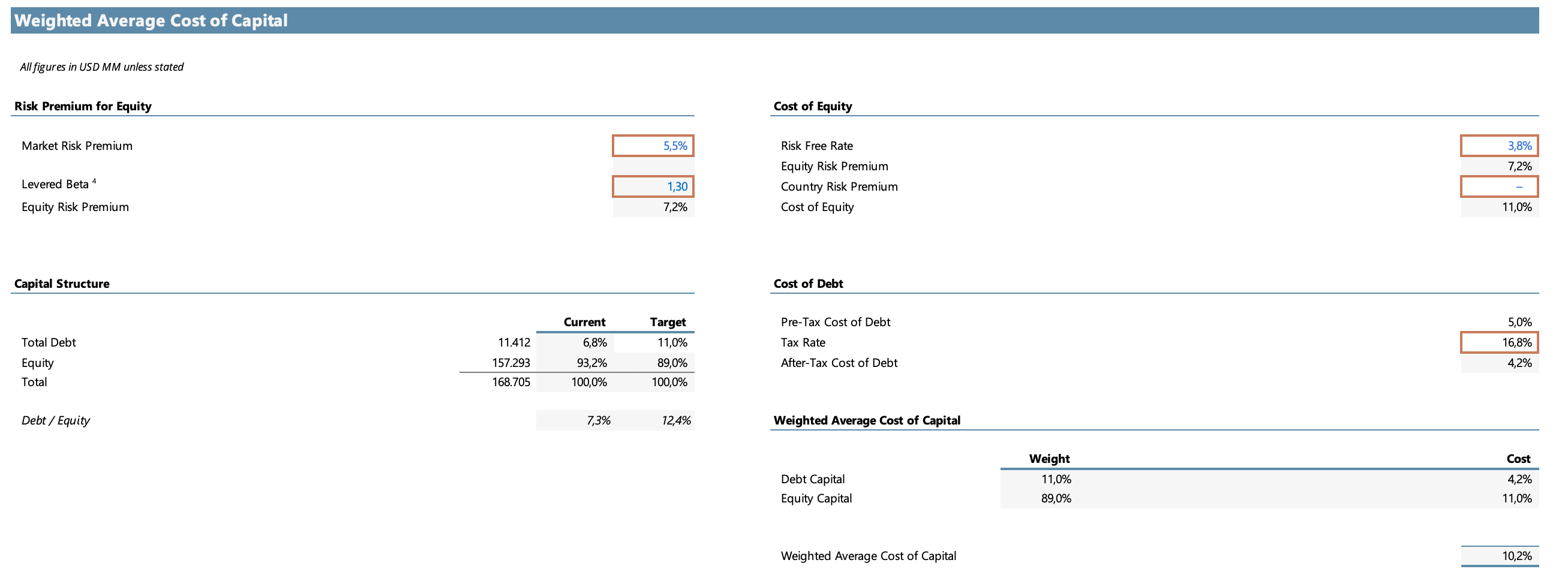
WACC (Weighted Average Cost of Capital): es la tasa de descuento que se utiliza para traer al presente los flujos de efectivo proyectados. En un DCF proyectamos lo que va a generar la empresa en el futuro y descontamos esos valores al presente utilizando esta tasa. Considerando las variables que se muestran a continuación, el resultado es un WACC del 10,2%, lo cual me parece razonable para el perfil de riesgo actual de Nvidia.
ESCENARIOS DEL MODELO
El modelo contempla tres escenarios:
Base Case: el escenario de mayor probabilidad de ocurrencia a mi criterio. Contempla que Nvidia mantendrá un rol protagonista en la infraestructura de IA, pero que el crecimiento de ventas al que nos tiene acostumbrados no será sostenible a largo plazo. Hay una desaceleración gradual tanto en ventas como en márgenes hasta llegar a un estado de madurez más estable.
Best Case: Nvidia logra mantener niveles de crecimiento y márgenes superiores al caso base durante más tiempo, aunque con cierta compresión inevitable hacia el final del período.
Worst Case: Nvidia enfrenta un deterioro más acelerado que el Base Case, impulsado por una mayor penetración de los ASICs en el mercado de inferencia y una maduración más rápida del sector.
RESULTADOS DEL MODELO
Método de Perpetuidad:
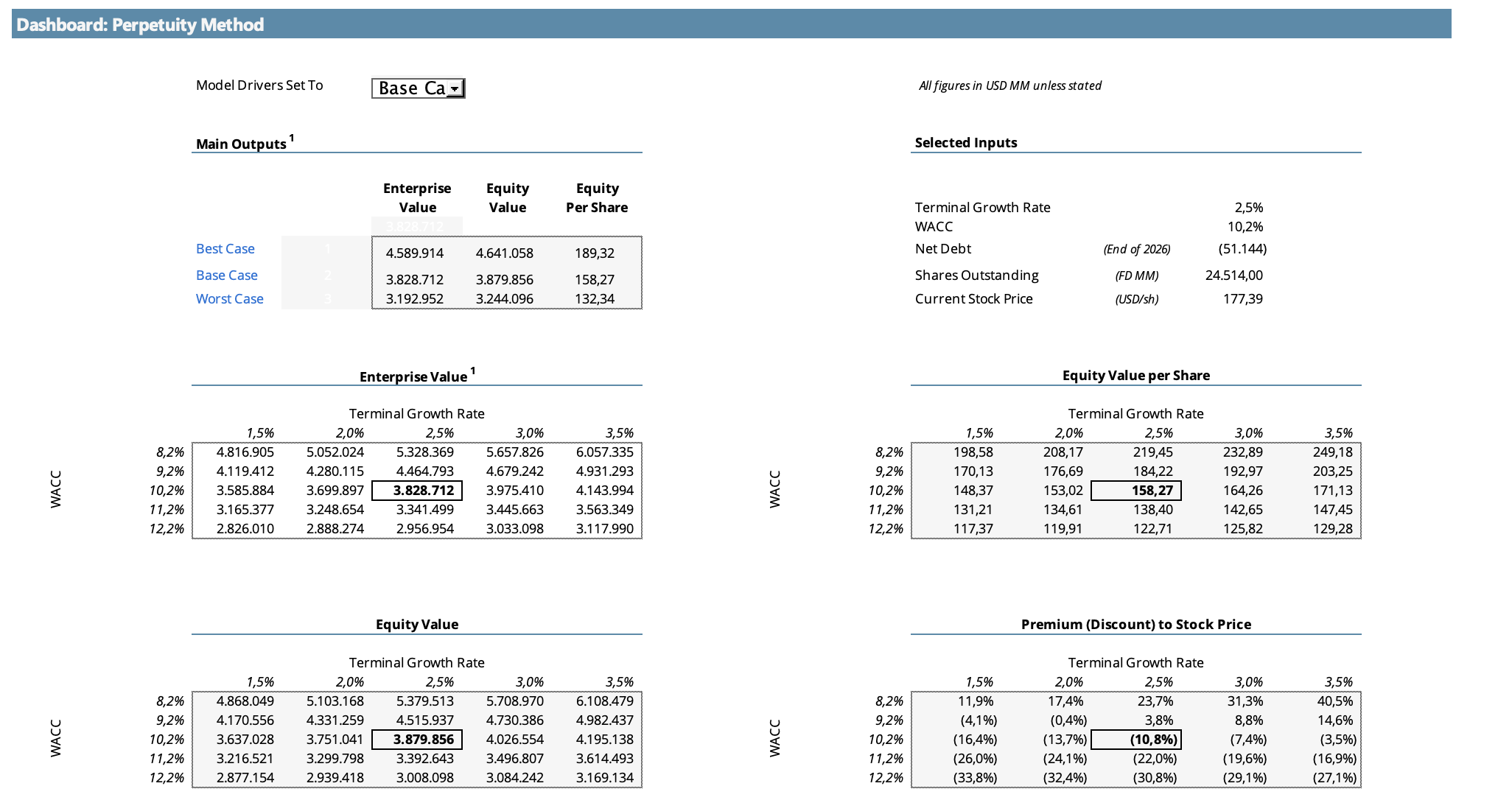
Proyectando un crecimiento terminal del 2,5% y descontando el flujo de efectivo a una tasa del 10,2%, obtenemos un valor intrínseco de $158 por acción. A los precios actuales, Nvidia estaría cotizando con una prima del 12% sobre este valor.
Método de Múltiplo EBITDA:
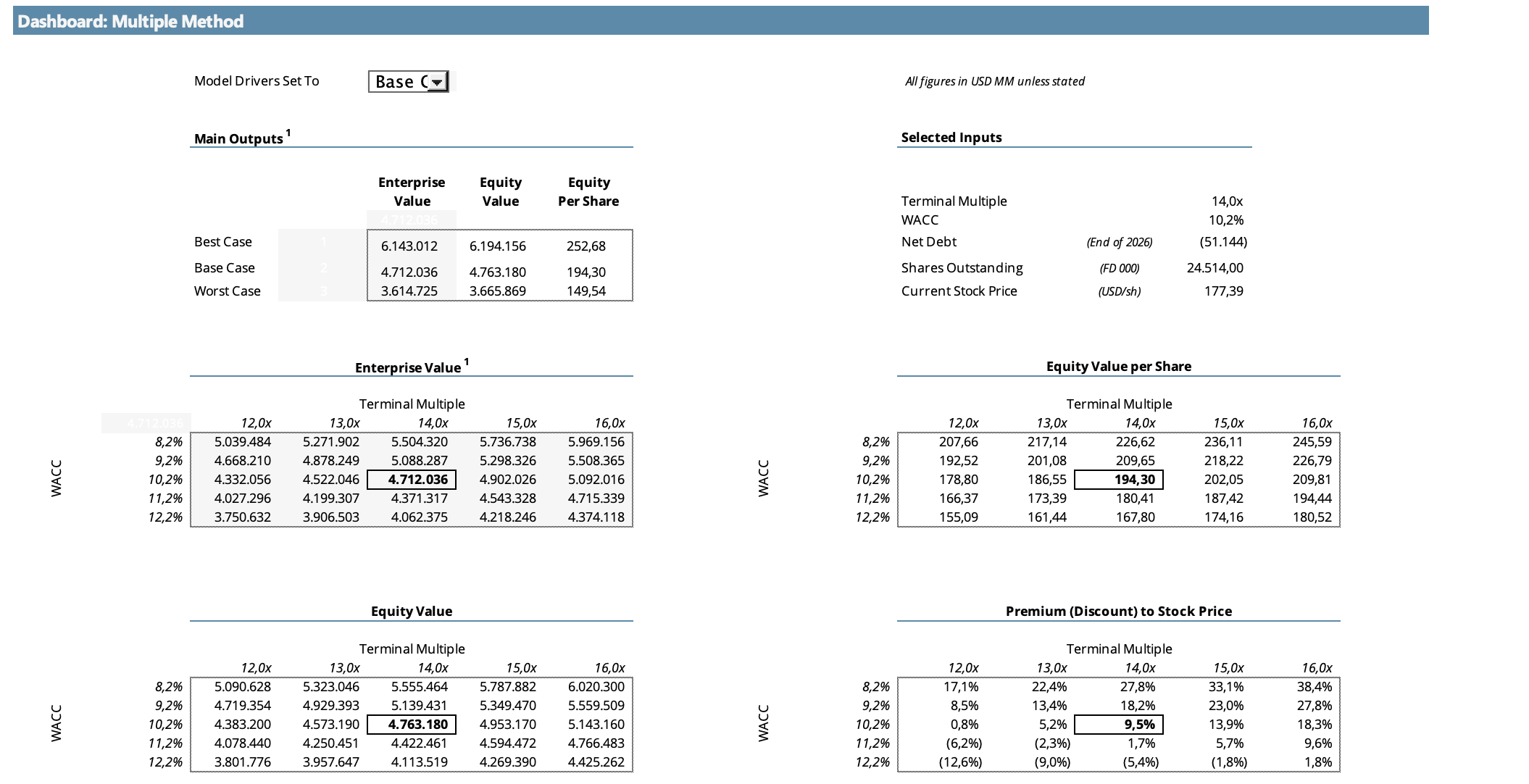
Aplicando un múltiplo de 14x sobre el EBITDA terminal obtenemos un valor intrínseco de $194 por acción. Bajo este método, Nvidia estaría cotizando con un descuento del 9% respecto a su valor intrínseco.
El precio actual de $177 se ubica prácticamente en el punto medio de ambas valoraciones, lo que sugiere que el mercado está descontando un escenario intermedio entre las dos visiones.
En ambos métodos puede verse un análisis de sensibilidad que muestra cuánto varía el precio por acción ante modificaciones en el WACC, la tasa de crecimiento terminal y el múltiplo de salida. Ambos modelos son muy sensibles a estas variables, lo que refleja la naturaleza inherentemente subjetiva de valuar una empresa en plena transición tecnológica. Acá es donde entra la parte más “artística” del análisis: los números dan un rango, pero la convicción sobre dónde dentro de ese rango se va a ubicar el valor real depende de cada inversor.
Conclusión
Nvidia es, sin discusión, la empresa más influyente de la era de la inteligencia artificial. Jensen Huang construyó durante 30 años el ecosistema que el mundo necesitaba sin saber exactamente cuándo lo iba a necesitar. Eso es visión de largo plazo ejecutada con consistencia extraordinaria.
El negocio es excepcional: márgenes de software en una empresa de semiconductores, FCF de $97B en un año fiscal, demanda que supera la oferta en todos los segmentos relevantes. El moat de CUDA es real y profundo.
Sin embargo, a los precios actuales el margen de seguridad es estrecho. El precio de mercado de $177 se ubica exactamente entre mis dos valoraciones, con el Perpetuity Method sugiriendo una prima del 12% y el Múltiplo Method un descuento del 9%. No es una empresa cara en términos absolutos, pero tampoco creo que amerite iniciar una posición considerando que hay mejores oportunidades actualmente.
Personalmente, tengo una posición muy reducida, habiendo vendido la mayor parte hace varios meses. Me gustaría incrementarla, pero para eso prefiero esperar una corrección más pronunciada que amplíe el margen de seguridad. Si tuviese una posición completa, de ninguna manera vendería a esta valoración. Simplemente creo que está bien mantenerla en ese caso, pero sí que es preferible esperar si tuviese que iniciar o ampliar posición.
Dicho esto, aun en el escenario más optimista no me sentiría cómodo teniendo una posición grande en Nvidia. Mi techo personal ronda el 8-10% del total de la cartera, y hay una razón concreta detrás de ese límite. A diferencia de otras empresas que prefiero y donde el moat me resulta más duradero y predecible (como Google o Meta, negocios con efectos de red prácticamente imposibles de replicar) Nvidia opera en una industria con una dinámica más cíclica de lo que la narrativa actual sugiere. Los ciclos de capex de los hyperscalers son volátiles, las arquitecturas de chips se vuelven obsoletas cada 12 a 18 meses y, lo más importante, los propios clientes más grandes de Nvidia están invirtiendo activamente para depender menos de ella: Google con sus TPUs, Amazon con Trainium, Meta con MTIA y OpenAI con su chip propio en desarrollo junto a Broadcom.
Siempre recuerdo una de mis primeras clases de economía, donde me dijeron algo que me quedó bastante grabado: la economía funciona por incentivos. Y los hyperscalers tienen exactamente esos incentivos. Cada punto porcentual de inferencia que migran fuera de Nvidia les ahorra miles de millones de dólares al año. Eso no invalida la tesis de Nvidia en el corto y mediano plazo, pero sí pone un techo razonable a la convicción que estoy dispuesto a tener en ella como posición de largo plazo.
Saludos,
Alan